Key Features
In this section, we will discuss the features and inner workings of the framework that enable implementation of the principles outlined in the previous section.
Data Model and Metadata
The unified data model approach allows you to avoid duplicating the data model across different layers and writing boilerplate code. This section explains how Jmix offers efficient methods for working with a single model of heterogeneous data.
Building Metadata
Let’s take a look at the various options for application data sources, ranging from simple to more complex.
In the simplest case, the application connects to a single relational database, and its data model consists of a number of interconnected JPA (Jakarta Persistence API) entities:

Sometimes data are located in several databases. Then you have multiple persistence units with JPA entities. If you need to connect to an external data source, then you also need some POJOs or DTOs to represent its data:

So in the source code, you can have separate collections of Java classes, differently structured and annotated, and handled by different mechanisms of loading and saving data.
Jmix combines all these fragments into a common data model and treats all classes as just "entities" with equal characteristics:

The data model can even contain references between entities from different storages (as shown by dotted lines) and Jmix helps to maintain these references on the application level.
The common data model with the unified information about all entities, attributes and relations is provided by the Metadata mechanism. It scans Java classes and represents entities by MetaClass objects and entity attributes by MetaProperty objects.
The picture below shows an example of how a couple of JPA entities are reflected in metadata:

Note that the employeeCount attribute here is transient and is not handled by JPA. But in metadata, it has the same set of characteristics as other attributes.
You may notice that the Java classes have some annotations specific to Jmix: @JmixEntity, @InstanceName, @Secret. The @JmixEntity annotation is required, it indicates that the class should be included in the metadata, the others are optional and just provide additional information about attributes.
You can add the @JmixEntity to any POJO, thus including it in the metadata as an entity. This is how the common data model is built - by annotating all model classes regardless of their storage technology.
Actually, the metadata API is rarely used in the application code. When you write business logic and code for loading and saving entities, you use Java classes and their getter/setter methods and enjoy static typing and coding assistance in the IDE.
But the unified API for the whole data model is indispensable for generic mechanisms of the framework, first of all for data-aware UI components. It provides an abstraction over various methods of specifying data model characteristics, so UI components are completely agnostic of Java classes and annotations. They can work equally well directly with JPA entities or with presentation layer POJOs created to transform the stored data for the UI.
An entity in Jmix can even be defined dynamically at runtime by a set of key-value pairs. Such entities do not have a specific Java class, but nevertheless can be displayed and edited in user interface. UI components do not need a Java class, they need only an object that can read/write properties by name, and a corresponding MetaClass with the collection of MetaProperty to describe these properties.
Entity Enhancement
Now we’ll briefly discuss another aspect of the unified data model maintained by Jmix: enhancement of entity classes, which is also known as bytecode modification or weaving. Jmix enhances entity classes at build time to provide required characteristics for all types of entities. These characteristics include the presence of an identifier, suitable equals() and hashCode() methods, ability to read/write entity attributes by name and listen to changes in attribute values.
For example, a DTO entity can have no identifier attribute if it is not stored in any persistent storage and exists purely in memory. But for uniformity with persistent entities, Jmix modifies the entity bytecode and adds an identifier field with automatically generated value. The same with equals() and hashCode() - they are added to the entity classes at build time with the implementation based on comparing identifiers.
The following diagram shows that after enhancement the User entity class implements the Entity interface, contains generated equals() and hashCode() methods and a reference to the EntityEntry object which provides common methods required by the framework:

An interesting feature that all entities acquire from enhancing is their observability. It is possible to register listeners with an entity instance and get notified about changes in its attributes. Using this feature, the framework simplifies working with data on UI layer: any changes in entities made by the application code, like user.setFirstName("Joe") are immediately shown by the linked UI components, and the changed entities are automatically saved in the database. The application developer doesn’t need to write any special code for this, it happens because the framework components listen to changes in entities.
Data Access
This section covers Jmix features related to accessing data in data stores.
DataManager
Jmix provides its own abstraction for loading and saving entities: DataManager. It has a simple fluent API:
// Load all customers
List<Customer> customers = dataManager.load(Customer.class)
.all()
.list();
// Load customers by query
List<Customer> customers = dataManager.load(Customer.class)
.query("e.email like ?1", "%@company.com")
.maxResults(1000)
.list();
// Load a customer by id
Customer customer = dataManager.load(Customer.class)
.id(customerId)
.one();
// Save a customer instance
dataManager.save(customer);The main reason for introducing DataManager was the need to establish a central point through which all data could flow in and out of data stores. It serves as a hub that provides additional data processing to enable Jmix functionality.
In a typical scenario, DataManager is invoked directly from UI views and REST controllers (if you build a REST API in your application). Both can delegate to a service layer, which in turn works with entities through the DataManager:

Jmix also supports the popular Spring Data API, which allows all data access methods for a particular entity to be concentrated in a repository. In this case, the repository interface should extend JmixDataRepository, then its implementation will delegate to the DataManager as well:

The capabilities that Jmix offers through the DataManager are listed below.
-
One of the key features of Jmix is its built-in data access control mechanism. By default,
DataManagerapplies row-level constraints and entity operations policy. As a result, when writing business logic, you can be sure your code operates only on data permitted for the current user. -
DataManagermaintains cross-datastore references that allow you to link entities located in different databases without writing any code. -
DataManagersends entity lifecycle events, which allows you to perform additional actions when loading and saving entity instances: copy data between persistent and transient attributes, update related entities, send notifications and so on. -
References of entities loaded using
DataManagercan be loaded lazily, when they are first accessed. This allows for easy navigation through the entity graph, regardless of what initial graph was loaded with the root entity:Order order = dataManager.load(Order.class).id(orderId).one(); String cityName = order.getCustomer().getAddress().getCity().getName(); -
DataManagersupports a pluggable mechanism for integrating add-ons into the process of loading and saving data. It is used, for example, by the Dynamic Attributes add-on to mix in dynamic attributes to entity instances and by the Search add-on to automatically send changed instances to indexing.
Jmix doesn’t prevent you from bypassing DataManager and accessing data stores through an alternative API like JPA EntityManager or JDBC:

However, in this case Jmix will not be able to intercept the data flow and provide its advanced features described above.
The DataManager does not perform all the work on its own. Instead, it delegates the actual loading and saving tasks to the DataStore implementations. The DataStore interface is an abstraction for a concrete storage system, such as a database or other service that can store entities.
Jmix contains two built-in implementations of the DataStore interface:
-
JpaDataStorecan work with entities located in a relational database, using theEntityManagerprovided by JPA (Jakarta Persistence API). -
RestDataStorecan work with entities mapped to the generic REST API of another Jmix application. ThisDataStoreimplementation is provided by the optional add-on.
An application or an add-on can provide custom DataStore implementations to work with entities from non-relational databases or from various web services.
So the DataManager itself serves mostly as a gateway, providing a convenient API and dispatching requests to DataStore implementations:

JPA Specifics
This section will explore the DataManager features provided by JpaDataStore and what Jmix adds on top of the standard JPA capabilities.
Loading Object Graphs
Jmix offers advanced ways of retrieving object graphs that are not available in the widely used implementation of JPA based on Hibernate. Below you can see an overview and motivation behind these features. For more details, see the Fetching Data section.
The first feature is lazy loading of references for detached objects, that is outside the initial transaction. You can traverse the whole object graph by accessing reference attributes at any time in your business logic or UI component bindings, and Jmix will load the related entities from the database on demand.
The second feature is about eager loading. Jmix offers the mechanism of Fetch Plans, similar to the JPA Entity Graphs. A fetch plan allows you to control the set of related entities loaded with the root one, and, optionally, the set of local attributes for each entity of the object graph. The ability to restrict the set of loaded local attributes can significantly reduce the database workload, especially in enterprise applications where entities with dozens or even hundreds of attributes are not uncommon.
The Jmix fetch plans provide a completely dynamic way to eagerly load your data model entities partially, without the need to introduce any static partial objects. As opposed to Jmix capabilities, the JPA Entity Graphs implemented by Hibernate allow you to define the loaded graph only at the level of related entities. In order to restrict the set of local attributes, you have to use a separate mechanism, for example Spring Data Projections, which requires more boilerplate code.
The ability to load partial entities for improving performance is the main reason why Jmix uses EclipseLink as a JPA implementation. On top of EclipseLink capabilities, Jmix adds convenient definition of fetch plans, automatic selection of fetch modes (JOIN or BATCH), and lazy loading that delegates to DataManager.
Soft Deletion
Another Jmix feature implemented at the JPA level is soft deletion. This is a popular approach in enterprise applications, as it helps to reduce the risk of data loss due to incorrect user actions.
Soft deletion in Jmix is fully transparent for a developer and easy to use. You can just add a couple of annotated attributes to your entity, and Jmix will record who and when "deleted" the entity instance in these attributes, instead of physically removing the row from the database table.
When loading entities by any JPQL query, the soft deleted instances will be automatically filtered out from the list of the root entity instances and from all nested collections (one-to-many and many-to-many references).
Moreover, the soft deletion in Jmix can be dynamically switched off for a particular operation. So depending on the situation, you can load either only non-deleted instances or both non-deleted and soft deleted ones. When the soft deletion is off, the delete operation actually removes the row from the database.
See more information in the Soft Deletion section.
User Interface
To adhere to the full-stack development principle, Jmix uses the Vaadin framework for user interface development. In this section, we describe features that Jmix adds on top of Vaadin to maximize the productivity of creating enterprise applications with large data models and UI.
Views
A Jmix application UI consists of a number of views. A view is a separate part of UI that serves a specific function. For example, a view can display a list of customers or manage customer attributes.
Jmix provides a set of base classes for views, typical for enterprise applications.
-
StandardMainViewhelps in building a main view which defines the root page with the application main menu. -
StandardViewis a generic purpose base class which can be used for creating any view opened from the main view. -
StandardListViewandStandardDetailVieware subclasses ofStandardViewdesigned for managing your data model entities.
The views in Jmix have several distinctive features, which are discussed in detail below.
Navigation and Dialogs
A view can be mapped to a URL and opened inside the main layout by navigating to this URL.
In addition, Jmix allows you to open the same view in a dialog window popped up on the current page without changing the URL. In the former case, the previous view will be closed, while the latter will keep the URL unchanged and the previous view open.
The ability to open any view in a dialog window is designed to satisfy two typical requirements in enterprise applications: selecting related entities and editing aggregates.
Let’s discuss the first requirement below and the second one in the subsequent section.
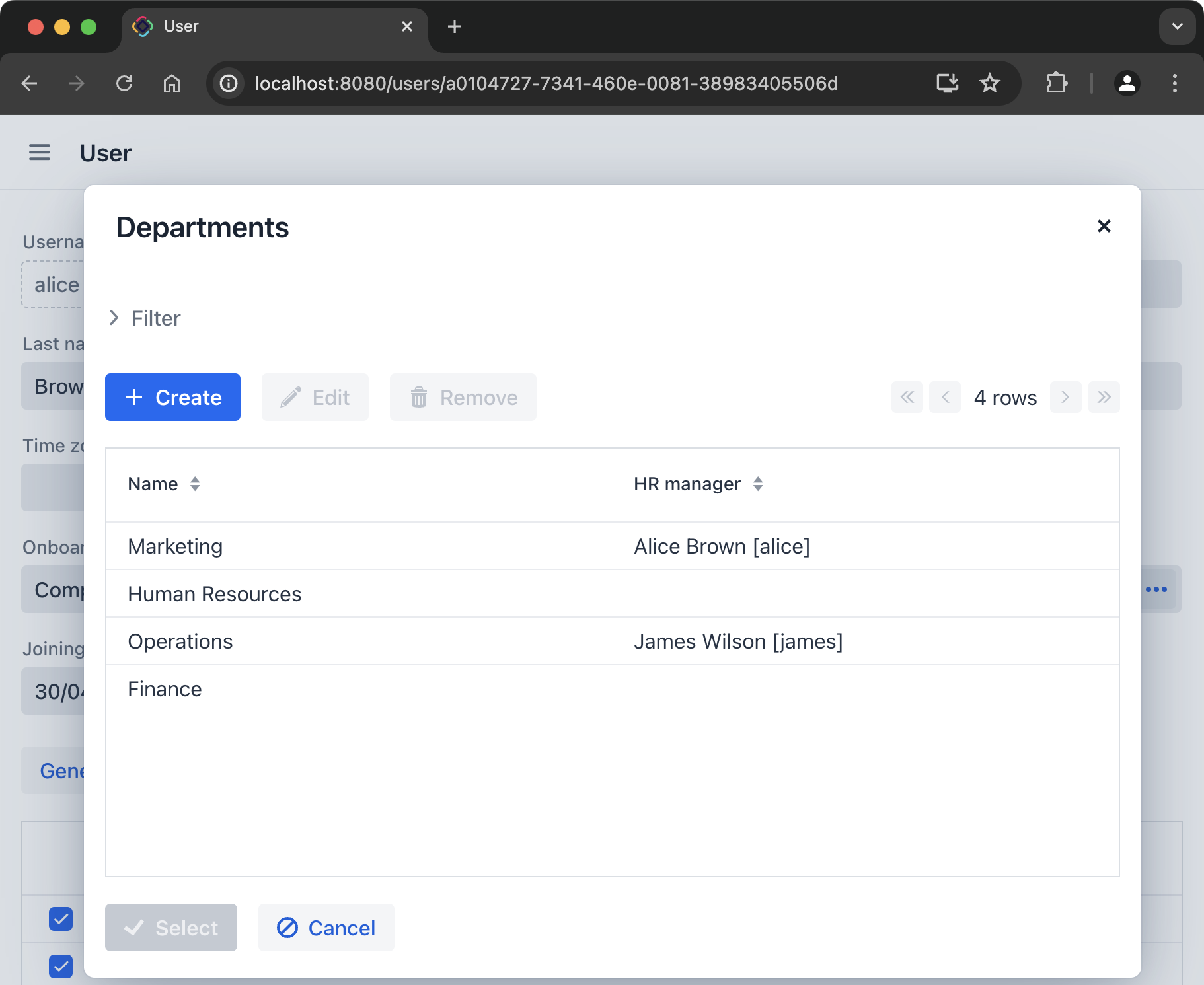
Usually web applications offer dropdown lists for selecting related entities. For example, when a user creates an order, they can select a related customer from a dropdown list displaying the names of all customers. But what if the customer should be found not by its name but by their VAT number or some other attribute? Or the customer isn’t registered yet and need to be entered along with the order?
Jmix offers a universal solution to the problem of advanced selection of related entities: it allows users to open a CRUD list view for the desired entity in a dialog window, find or create the entity instance and return it from there. This feature is implemented by a special action in the UI components for selecting entities. By default, it uses the same CRUD view as for managing entities, but you can create a specific view for the lookup.
Opening a lookup view in a dialog, which doesn’t destroy the original view, makes returning results from the opened view straightforward - they are just passed as Java objects on the server side.
Dialog windows with lookup views can automatically stack on top of each other, providing the way to drill down into your data model without losing the initial context. For example, when creating an order, a user can open the list of customers in a dialog, then create a customer in a separate dialog, then create a customer’s contact in its own dialog, and finally select the customer and continue editing the order. Jmix provides this functionality out-of-the-box by reusing the CRUD views created for managing entities in the application.
XML Descriptors
The content of a view can be defined in XML. This approach allows you to concisely and expressively describe the structure of UI components and set their properties. Also, for non-trivial views the readability of XML is much higher than that of imperative code which instantiates components, sets their properties, adds components to containers, and assigns event listeners.
XML has the following advantages over other markup languages:
-
Provides complete syntax for describing the UI component tree: elements for components and attributes for their properties. Supports comments.
-
Can be validated using XSD. An IDE provides code completion based on XSD without any additional tooling.
-
Is extensible with namespaces.
-
Can be easily generated, parsed and transformed.
-
Is widely known by developers.
A Jmix view usually points to its XML definition file using the @ViewDescriptor annotation on the view class. After instantiating the view, the framework reads the XML and builds the corresponding component tree. The view class can contain methods, associated with the components: event listeners and delegates, which are discussed in the next section. The view components can be injected into class fields, so the view methods can easily access the components and their properties.
Handlers
A view has a specific set of lifecycle events and provides a declarative way to subscribe to all UI events (generated by the view and its components) using annotated methods.
Event listeners are marked with the @Subscribe annotation, for example:
@Subscribe
public void onReady(ReadyEvent event) {
// the view is ready to be shown
}To subscribe to a component event, the component id is provided in the annotation:
@Subscribe("generateButton")
public void onGenerateButtonClick(ClickEvent<Button> event) {
// the button with `generateButton` id is clicked
}When loading the view, Jmix automatically creates a MethodHandle for each annotated method and adds it as a listener for the corresponding component. So the examples above are declarative substitutes for the following imperative code:
@ViewComponent
private JmixButton generateButton;
private void assignListeners() {
addReadyListener(this::onReady);
generateButton.addClickListener(this::onGenerateButtonClick);
}
public void onReady(ReadyEvent event) {
// the view is ready to be shown
}
public void onGenerateButtonClick(ClickEvent<Button> event) {
// the button with `generateButton` id is clicked
}The Jmix approach with annotated methods reduces boilerplate and allows IDE to reliably associate UI components with their event handlers. As a result, Jmix Studio contains the component inspector panel which displays all existing handlers for a component, and allows you to go to their source code and generate new ones.
There are two other annotations similar to @Subscribe: @Install and @Supply. They indicate methods that are not associated with specific events, but simply need to be invoked by components for a particular purpose. For example, the following method is invoked by the text field to validate the entered value:
@Install(to = "usernameField", subject = "validator")
private void usernameFieldValidator(final String value) {
// check the field value
}View State
Jmix provides a set of abstractions for working with the view state. They allow for coordinated loading and saving data, as well as for declarative binding UI components to the loaded entities.
Data Binding
The central element of this feature are data containers that hold data loaded into the view. There are two types of data containers: InstanceContainer holds a single entity instance and CollectionContainer holds a list of entities.
Data containers are usually declared in the view XML, together with the UI components tree. This enables declarative binding of UI components to entities and their attributes loaded into data containers:
<data>
<instance id="userDc" class="com.company.onboarding.entity.User"> (1)
<collection id="stepsDc" property="steps"/> (2)
</instance>
</data>
<layout>
<textField id="usernameField" dataContainer="userDc" property="username"/> (3)
<dataGrid id="stepsDataGrid" dataContainer="stepsDc"> (4)
<columns>...</columns>
</dataGrid>| 1 | The userDc data container holds an instance of User entity. |
| 2 | The nested stepsDc data container is associated with the steps collection property of the User entity. Nested data containers mirror the loaded object graph. |
| 3 | The text field edits the username property of the User entity located in the userDc data container. |
| 4 | The data grid displays the collection of Step instances located in the stepsDc data container. |
Apart from data binding for UI components, data containers provide state change events that can be used in the view logic. For example, ItemPropertyChangeEvent notifies that the value of an entity attribute has been changed. This event is not sent when the view is populated with initial values, so it is better suited to tracking state changes than value change events sent by UI components.
Loading Data
Data containers are usually combined with another Jmix UI abstraction - data loaders.
In view XML, data loaders are defined within associated data containers:
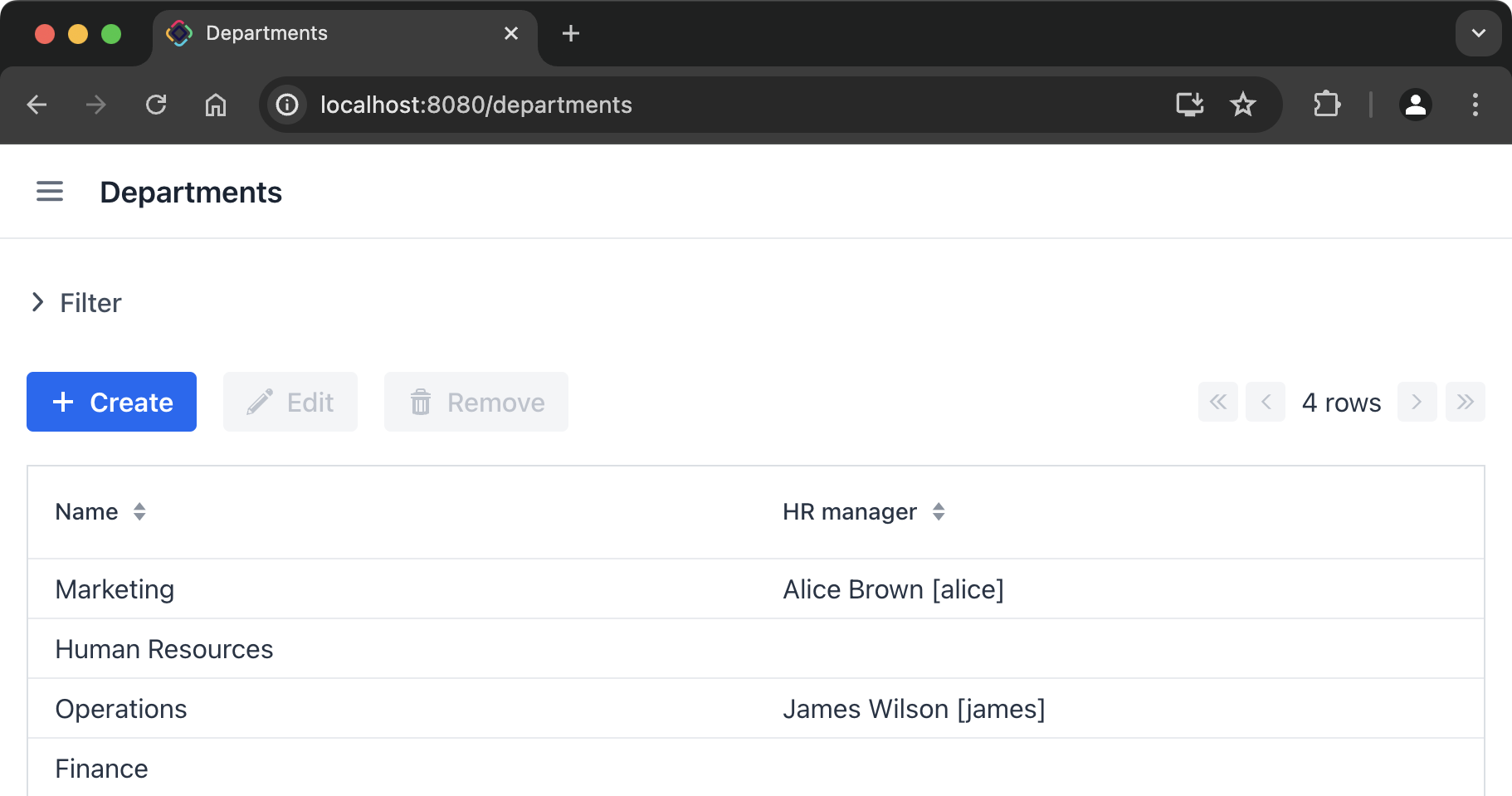
<collection id="departmentsDc" class="com.company.onboarding.entity.Department">
<loader id="departmentsDl">
<query>
<![CDATA[select e from Department e]]>
</query>
</loader>
</collection>In the example above, the loader contains a JPQL query that will be passed to DataManager to load JPA entities.
A loader can delegate the loading logic to an annotated view method, for example:
@Install(to = "departmentsDl", target = Target.DATA_LOADER)
private List<Department> departmentsDlLoadDelegate(LoadContext<Department> loadContext) {
return departmentService.loadAllDepartments();
}Such a delegate enables loading entities from an arbitrary service or data repository.
The purpose of the loader is to collect loading criteria (ID, query, conditions, pagination, sorting, fetch plan, etc.) in the LoadContext object, invoke the DataManager or a delegate, and populate the associated data container with the loaded entities.
Data containers can also be populated programmatically without loaders, using their setItem() and setItems() methods.
Saving Data
Jmix UI offers a mechanism for automatically saving entities changed in a view. It is based on the DataContext interface.
Do not confuse DataContext with DataManager explained above. DataContext is a UI feature, while DataManager is a generic data access interface that can be used on any layer.
A view creates a single instance of DataContext, and all data loaders register entities with it before passing them to data containers.
The DataContext implementation maintains an in-memory structure with references to all entities loaded into the view. When an entity is created, updated or deleted in UI, the data context marks this entity as "dirty".
When the user saves the view (for example, by clicking the OK button), the view invokes the DataContext.save() method and data context saves the dirty entities using DataManager or by invoking a delegate method defined in the view.
The Jmix data context functions similarly to the JPA persistence context, which tracks changes in loaded entities within a transaction and automatically saves changes upon transaction commit.
DataContext objects can form hierarchies, where child contexts save changes to the parent ones instead of directly to the persistence layer. This feature plays crucial role for editing aggregates, discussed in the next section.
Editing Aggregates
A data model can contain complex structures called aggregates. This term was introduced in the Domain Driven Design approach. You can find a good explanation of it in this article.
Let’s consider a model containing the Customer, Order, OrderLine and Product entities. Each OrderLine instance is created for a particular Order and becomes its part, it cannot belong to another Order. At the same time, Customer and Product are independent entities that can be referenced from multiple instances of different entities. So the Order and OrderLine entities form an aggregate, with Order being the aggregate root:

The aggregate state should always be consistent, so OrderLine instances should be updated together with the owning Order in the same transaction. From the user’s perspective, changes in order lines must be saved only when the user confirms the changes in the order.
Jmix allows you to organize the editing of aggregates using simple CRUD views without the need to write any custom code. All you have to do is to mark the reference from the aggregate root to its components with the @Composition annotation. For example:
@JmixEntity
@Entity(name = "Order_")
public class Order {
// ...
@Composition
@OneToMany(mappedBy = "order")
private List<OrderLine> lines;This annotation is added when you specify COMPOSITION as the attribute type in the Studio entity designer.
As a result, when editing Order and OrderLine entities using their detail views, Jmix establishes a parent-child relationship between data contexts of these views. So, when the user confirms changes in the OrderLine detail view, it will update corresponding instances in the parent Order view. And only after confirming the Order, the entire aggregate is sent to DataManager (or a custom service) for saving in the database in a single transaction.
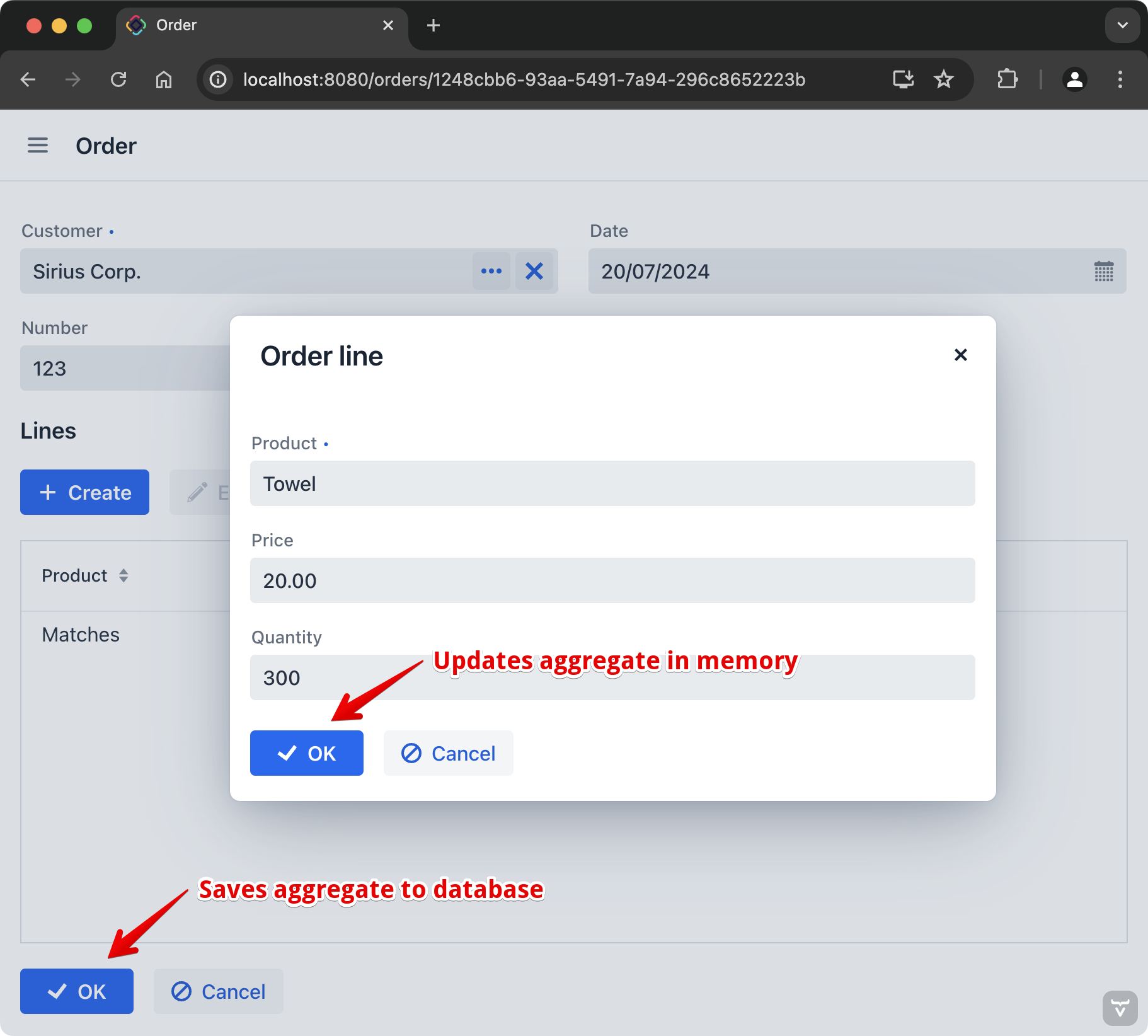
Jmix supports aggregates with multiple levels. In the previous example, you might have a collection of notes for each OrderLine. Then to include the Note entity in the aggregate with the Order root, you would simply have to annotate the reference from OrderLine to Note with @Composition.
For a more detailed understanding of this topic, refer to the Data Modeling: Composition guide.
Security
Effective security and data access control are essential components of any enterprise application. Jmix is secure by design and offers the following features:
-
Out-of-the-box configuration for authentication based on Spring Security.
-
Sophisticated data access control mechanism.
-
Built-in roles and permissions management.
The Jmix security concepts are thoroughly described in the dedicated Security section. Here we will just discuss its relation to the basic Jmix principles.
-
The full-stack nature of Jmix with Java all the way from backend to UI enables fully integrated declarative access control, which is also very easy to manage.
For example, if you want to disable an entity attribute to a user, you just remove the permission to this attribute from a role granted to the user. The views displaying this attribute in UI components (text fields, data grid columns, etc.) will automatically make these components invisible. As a result, the attribute value will not be transferred over the wire and won’t be present in the user’s browser.
The same is for row-level security: you write a JPQL-based and/or predicate policy, and DataManager filters out the entity lists no matter where and how you request this entity: through the DataManager or data repository, using eager or lazy loading, as a root entity or as a collection attribute of another entity.
-
The unified data model contributes to the simplicity of the security management. Data access control is not scattered over the entire codebase in the form of annotations and "if" statements. Instead, it’s concentrated around a consistent structure of entities, their attributes and operations.
-
The security subsystem is a widely used ready-made component of Jmix. It works out-of-the-box in most scenarios.
-
The authentication mechanism of Jmix security is based on the mainstream Spring Security framework and allows developers to use their existing knowledge to configure it and integrate with third-party authentication solutions.
-
The Jmix security subsystem is highly extensible. Its authentication part can be configured to its core thanks to Spring Security. The authorization mechanism allows you to implement custom attribute-based access control (ABAC) if needed.
