Process Artifacts
Overview
During the lifecycle of a process, various artifacts are created. Understanding these artifacts is crucial for effectively managing and implementing business processes.
In the diagram below, you can see how these artifacts are related. Initially, the user creates a process model, which is represented by an XML file. Typically, one XML file contains a single process model. However, in the case of a collaboration model, multiple process models may be included within one XML file.
Next, processes must be deployed to the server. This occurs in two steps:
-
First, a deployment object is created. This object serves as a batch that can contain several process models, allowing for implementation in a single action.
-
Second, for each process model included in the deployment, a process definition is created.
To initiate a process, the server then generates a process instance object. At runtime, for specific branches (or paths) of the process, execution objects may be created.
Finally, the process instance can either be transformed into a historic process instance or deleted.
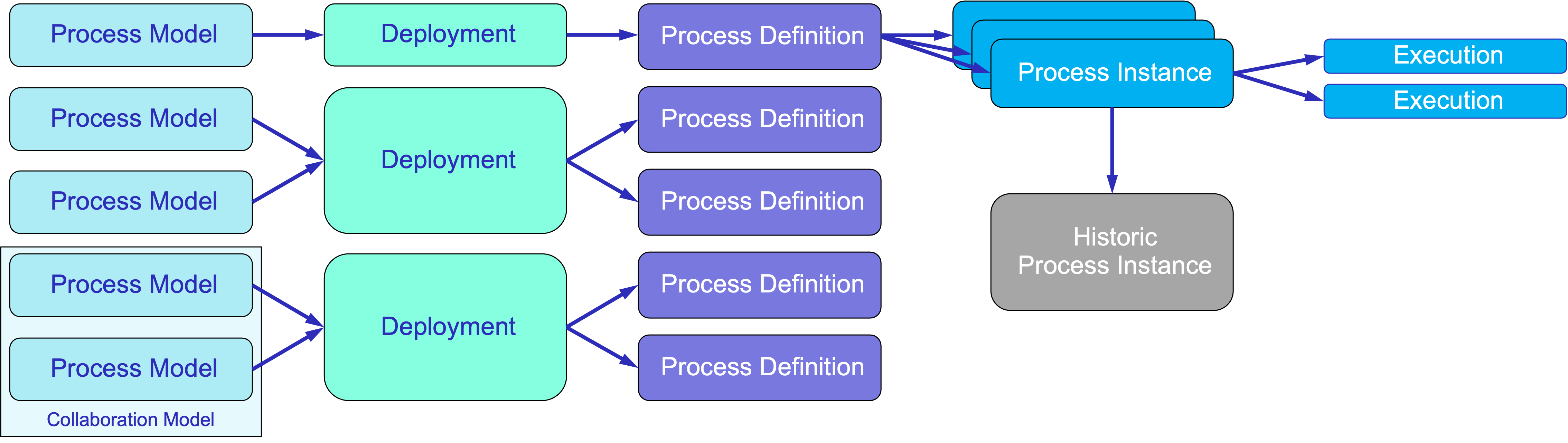
Below is a detailed description of the mentioned artifacts:
Process Models
In Jmix BPM, a process model refers to the structured representation of a business process, defined in an XML format using the BPMN 2.0 standard. The structure of a BPMN process model consists of several key sections that together describe the behavior and flow of the business process.
The <definitions> section serves as the root element of the BPMN XML file.
It encapsulates the entire process model and provides context for the various components defined within it.
This section typically includes metadata about the model, such as the XML namespace and the schema location,
which ensures that the document adheres to the BPMN standard.
Within the <definitions> section, you will find either a <process> or a <collaboration> element.
The <process> element defines a single process with its associated activities, events, and gateways.
This is the most common structure used when modeling a straightforward business process.
On the other hand,
the <collaboration> element is used when multiple processes interact with each other,
allowing for a more complex representation of workflows involving different participants or entities.
In this case, a collaboration model is created.
The model also includes event definitions for messages, signals, and errors.
Finally, the <diagram> section provides a visual representation of the process model, typically using a graphical notation.
This section is useful for human readers and process designers, as it allows them to visualize the flow and structure of the process.
Although the diagram does not affect the execution of the process, it enhances understanding and communication among stakeholders.
Below is an example of the visual process model in BPMN 2.0 notation and its XML representation:
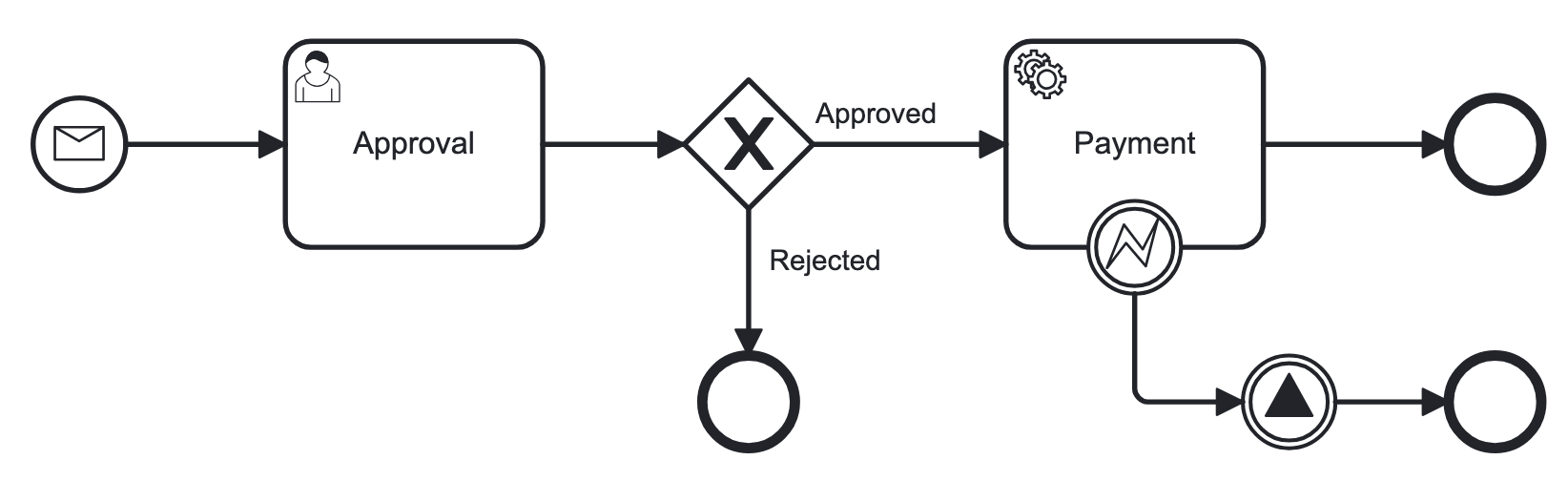
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL" <!--Other namespases.... --> >
<!--Process definition-->
<process id="document-approval" name="Document approval" isExecutable="true">
<!--Process elements-->
<process/>
<!--Event definitions-->
<message id="start-approval-process" name="Start approval process" />
<signal id="payment-failed" name="Payment failed" flowable:scope="global" />
<error id="payment-serice-error" name="Payment serice error" errorCode="900" />
<!--Diagram section-->
<bpmndi:BPMNDiagram id="BPMNDiagram_process">
<!-- Diagram elements -->
<bpmndi:BPMNDiagram/>
</definitions>Drafts and Processes
Conceptually, a process model exists in two states: draft and ready for deployment. Technically, both versions are valid BPMN models; the primary distinction lies in their storage locations. And the draft version has an additional extension labeled “.draft”.
Storing Process Models
Typically in Studio, process models are stored in src/main/resources/process-drafts directory for drafts
and in src/main/resources/processes for processes ready for deployment.
You can change where process models are located using Flowable Application Properties, but we recommend to use default locations.
As well, you can create atd store drafts at runtime using the Web Modeler.
|
Drafts in Studio and in the web application refer the different storages. They are not synchronized and contain different sets of models. |
Deployments
A deployment object serves as a container for various resources related to business processes, such as BPMN process models, images, forms, and other artifacts.
Business Archive
To deploy processes, they have to be wrapped in a business archive (BAR). A business archive is the unit of deployment to a process engine. A business archive is equivalent to a ZIP file. It can contain BPMN 2.0 processes, DMN rules, and any other type of file. In general, a business archive contains a collection of named resources.
When a business archive is deployed, it is scanned for BPMN files with a .bpmn20.xml or .bpmn extension.
Each of those will be processed and may contain multiple process definitions.
When the DMN engine is activated, .dmn files are also parsed.
|
Jmix BPM doesn’t use Flowable forms. |
Creating Deployments
In Jmix BPM, deployments can be created programmatically or by using UI features.
Programmatically, deployments are created using the DeploymentBuilder interface through RepositoryService.
The resources are added to the deployment using methods such as addClasspathResource, addInputStream, or other methods.
Once all resources are included, the deployment is finalized with the deploy() method:
repositoryService.createDeployment()
.name("My Deployment")
.addClasspathResource("processes/my-process.bpmn") (1)
.addString("greeting", "Hello, world!") (2)
.deploy();| 1 | — Adding a BPMN process model as an XML file. |
| 2 | — Adding a resource as a string. |
In Studio, processes are deployed automatically, see Automatic Deployment section for details. Or you can deploy them using the Hot deploy feature in Studio.
In Web Modeler, you can deploy processes manually.
Once a deployment is completed, the deployment object becomes read-only. This means that its contents cannot be changed after deployment, ensuring the integrity of the deployed resources.
Upon deployment, Flowable parses the BPMN XML files included in the deployment. For each BPMN file parsed, Flowable creates one or more process definitions. Each process definition is an internal representation of the process defined in the BPMN XML.
Accessing Deployed Resources
To access deployed resources at runtime:
//List the resources in the deployment:
List<String> resourceNames = repositoryService.getDeploymentResourceNames(deploymentId);
//Retrieve a specific resource:
InputStream resourceStream = repositoryService.getResourceAsStream(deploymentId, "my-resource.txt");Storing Deployments
The created process definitions are stored in the Flowable database, specifically in table ACT_RE_DEPLOYMENT.
Deleting Deployments
To delete a deployment in Flowable, you can use the RepositoryService to remove the deployment object.
// Specify the deployment ID you want to delete
// Replace with your actual deployment ID
String deploymentId = "yourDeploymentId";
// Delete the deployment
// The second parameter indicates whether to cascade delete process instances
repositoryService.deleteDeployment(deploymentId, true);The first parameter is the deployment ID, which you can obtain when you create a deployment or by querying existing deployments.
The second parameter (true or false) determines whether to cascade the deletion to all process instances associated with that deployment.
If set to true, all active and historic process instances created from this deployment will also be deleted.
If cascade deletion is set to false,
any active or historic process instances created from the processes defined in that deployment will not be deleted.
This means that while the process definitions are no longer available for new instances,
the existing instances remain intact in the system.
|
You can delete a certain deployment manually in the Process Definition Detail view. But keep in mind that this operation deletes ALL process definitions deployed together. |
Deployment Properties
A deployment has the following properties:
| Property | Description |
|---|---|
Id |
A unique identifier for the deployment. |
Name |
A descriptive name for the deployment, helping to identify it among multiple deployments. |
Deployment Time |
The timestamp indicating when the deployment was created. |
Resources |
A collection of resources (e.g., BPMN files, DMN tables) included in the deployment. |
Version |
The version number of the deployment, helping manage updates and changes to process definitions over time. |
Process Definitions
A process definition object represents a blueprint for an executable business process. It encapsulates the structure, activities, and logic of a process, allowing the process engine to manage and execute process instances based on the defined process model.
Creating Process Definitions
It is not possible to create process definition directly. Process definitions are created during the deployment process.
Each process definition is associated with a specific deployment, which acts as a container for one or more process definitions and related resources.
To see a list of process definitions, deployed to the engine, use BPM→ Process definitions view.
Suspending and Activating
Process definition has two states: active and suspended.
-
Active state: In this state, the definition can be used to create and execute processes based on its defined structure.
-
Suspended State: In this state, no new instances can be started from this definition, but existing instances that were already running can continue until they complete or are terminated.
Transition between states:
// Suspending a process definition
repositoryService.suspendProcessDefinitionByKey(processDefinitionKey);
// Activating a suspended process definition
repositoryService.activateProcessDefinitionByKey(processDefinitionKey);As well, you can suspend and activate process definition by ID.
Versioning of Process Definitions
During deployment, the process engine assigns a version to the process definition before it is stored in the database. Thus, process definitions are versioned, allowing multiple versions of the same process to exist simultaneously.
The id property is set to
{processDefinitionKey}:{processDefinitionVersion}:{generated-id},
where generated-id is a unique number
added to guarantee uniqueness of the process ID for the process definition caches in a clustered environment.
|
The property |
Accessing Process Definitions
To access process definitions at runtime:
// Querying for all process definitions in deployment
List<ProcessDefinition> processDefinitions = repositoryService.createProcessDefinitionQuery()
.deploymentId(deploymentId)
.list();
// Querying for all versions of the process definition
repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.list();
// Querying for the latest version of the process definition
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.processDefinitionKey(key)
.latestVersion()
.singleResult();Storing Process Definitions
The created process definitions are stored in the database, specifically in table ACT_RE_PROCDEF.
Deleting Process Definition
If you need to delete a process definition, you have to delete the associated deployment object. See Deleting Deployments section.
Process Definition Properties
A process definition in Flowable has several important properties:
| Attribute | Description |
|---|---|
ID |
A unique identifier for the process definition. |
Key |
A key that uniquely identifies the process definition across versions. (Important: In the process model this parameter is called |
Name |
A descriptive name for the process definition. |
Version |
The version number of the process definition. |
Deployment ID |
The deployment, this process definition belongs to. |
Resource Name |
The name of the BPMN XML file that defines the process. |
Category |
User-defined parameter. |
Process Instances
A process instance represents a running instance of a business process. It encapsulates the execution of a specific process definition, with its own state and data.
Process Instance Lifecycle
The lifecycle of a process instance encompasses several stages that represent the various states and transitions of a running process.
Creation
A process instance is created when a new instance of a process definition is started.
This can be done using the RuntimeService with methods like startProcessInstanceByKey or startProcessInstanceById.
The BPM administrator can manually start the process using the Process Definitions view. Users with the appropriate permissions can initiate processes using the Start Process view.
During this stage, initial variables can be passed to the instance, which can influence its execution.
// Example variable for the process
Map<String, Object> variables = new HashMap<>();
variables.put("employeeId", "12345");
ProcessInstance processInstance = runtimeService
.startProcessInstanceByKey("my-process", variables);ProcessInstanceBuilder builder = runtimeService.createProcessInstanceBuilder()
.processDefinitionKey("myProcess")
.businessKey("holidayRequest-123")
.variable("employeeId", "12345")
.start();
ProcessInstance processInstance = builder.start();Active State
Once created, the process instance enters an active state, where it begins executing tasks as defined in the process definition. The instance will progress through various tasks, events, and gateways defined in the BPMN model.
Query to check if the process instance is active:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.active()
.singleResult();If the process instance was suspended, you can activate it.
runtimeService.activateProcessInstanceById(processInstanceId);Suspended State
A process instance can be suspended, which temporarily halts its execution without terminating it. This allows for maintenance or updates without losing the current state of the instance. While suspended, no tasks will be executed, but existing tasks can still be viewed.
You can suspend a process instance using a Process Instance Detail view or programmatically:
runtimeService.suspendProcessInstanceById(processInstanceId);Query to check if the process instance is suspended:
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(processInstanceId)
.suspended()
.singleResult();Completion
When all tasks and events in the process instance are completed, it is considered completed too. But there is no special state completed. At this point, completed process instance is to be deleted, and the corresponding historic process instance is created. This historical data can be queried for reporting and auditing purposes.
Any variables that were set during the execution of the process are finalized and stored in the history, allowing for retrieval and analysis post-completion.
Upon completion, process engine may trigger specific events defined in the BPMN model, such as end events or signals, which can initiate further actions or notifications within the system.
|
There is no method to directly call a "complete" action on a process instance itself. Instead, you can manage the completion by handling tasks and ensuring that all conditions defined in the BPMN model are satisfied. |
Termination
A process instance can also be terminated before completion. This forcibly stops its execution and releases any resources associated with it. Terminated instances are no longer active and cannot be resumed.
If the terminated process instance is part of a larger workflow, its termination may affect the completion status of parent processes.
runtimeService.deleteProcessInstance(processInstanceId, "Reason for termination");|
In Flowable process engine, the concepts of termination and deletion can be considered equivalent when referring to process instances. |
A process instance can only be deleted if it is not currently executing any tasks. If there are active tasks, you will need to ensure that they are completed or that the instance is in a wait state before attempting deletion.
If the process instance has asynchronous tasks running, you may encounter a concurrent update exception. This happens because the process engine uses optimistic locking, meaning only one transaction can modify a row in the database at a time. If another transaction updates or deletes the same row while you’re trying to delete it, an exception will be thrown.
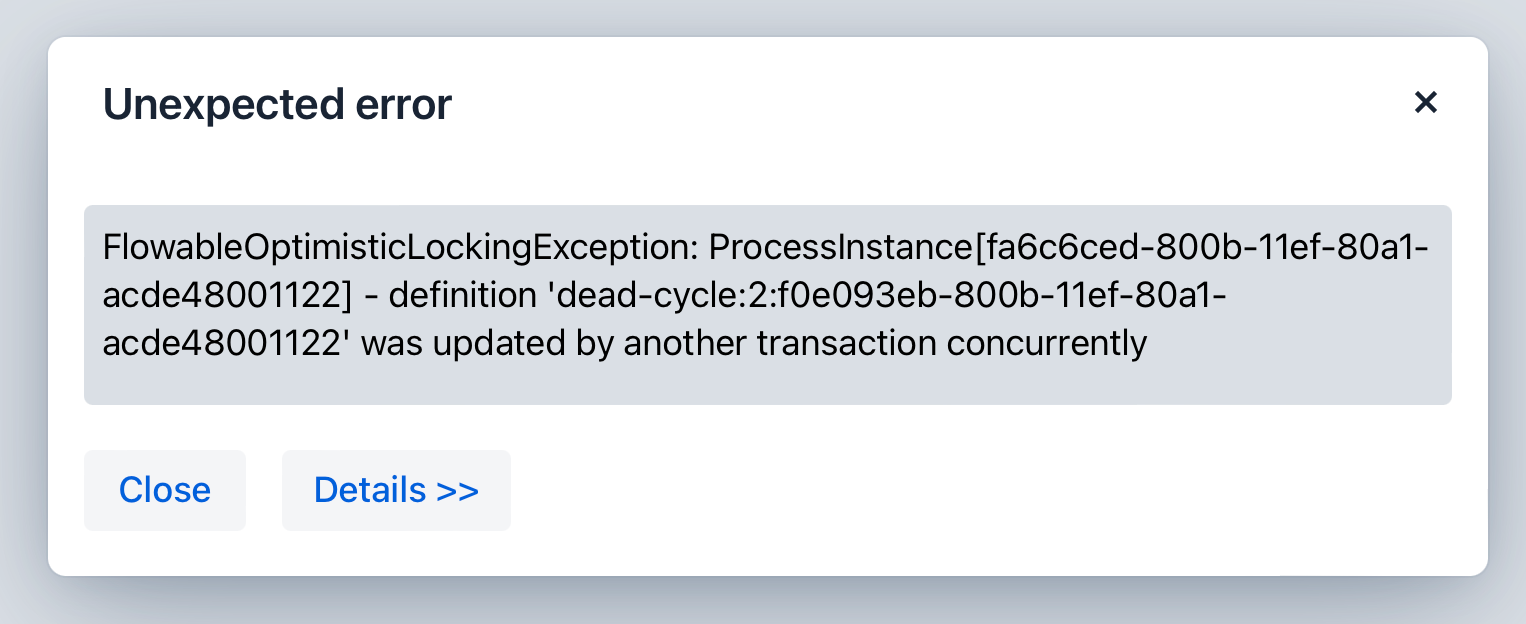
When a process instance is deleted, process engine does not trigger any listener events associated with the deletion action. This means you cannot implement custom behavior directly tied to the deletion event through listeners.
Accessing Process Instances
To access process instances at runtime:
// Querying for all instances of a specific process definition
List<ProcessInstance> instances = runtimeService.createProcessInstanceQuery()
.processDefinitionKey(key)
.list();
// Querying for a specific process instance by ID
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery()
.processInstanceId(instanceId)
.singleResult();Storing Process Instances
Process engine stores process instances together with executions in the table named ACT_RU_EXECUTION.
Process Instance Properties
| Property | Description |
|---|---|
Process Instance ID |
A unique identifier for the process instance. |
Business Key |
An optional business-level identifier for the process instance. |
Parent ID |
If this field is null, it indicates that the execution is a process instance. Otherwise, if it contains a value, it signifies that the execution is a child execution of a process instance. |
Process Definition ID |
The ID of the process definition that the instance is based on. |
Start Time |
The timestamp when the process instance was started. |
End Time |
The timestamp when the process instance was completed (if applicable). |
Duration |
The duration of the process instance execution. |
State |
The current state of the process instance (e.g., running, suspended, completed). |
Variables |
The data variables associated with the process instance. |
Executions
An execution object represents a "path of execution" within a process instance. It is a fundamental concept in the Flowable engine that allows for tracking the current state and flow of a process as it progresses through various activities.
|
Process Instance vs. Execution:
|
Executions are organized in a hierarchical tree structure. A process instance is also considered as top-level execution that may have child executions representing subprocesses or parallel activities. Even in a straightforward process, process engine creates an execution under the process instance.
The method getParentId() allows you to retrieve the ID of the parent execution,
establishing a clear relationship between parent and child executions,
which is essential for managing complex workflows.
Child executions can hold local variables that are specific to their context.
Accessing Executions
To specifically query for child executions of a particular process instance:
List<Execution> childExecutions = runtimeService.createExecutionQuery()
.processInstanceId(processInstanceId)
.list();Storing Executions
Both process instances and executions are stored in the ACT_RU_EXECUTION table.
This table contains records for both types of entities, which can complicate querying and management.
Deleting Executions
You cannot delete an individual execution that is part of an active process instance without deleting the entire process instance. Executions are tightly coupled with their parent process instance, and they represent the current state of that instance.
In cases of multi-instance tasks, you can use the deleteMultiInstanceExecution method to delete all executions related to a multi-instance activity, but this still relates to the context of the parent process instance.
// Replace with your execution ID
String executionId = "yourExecutionId";
// Set to true if you want to mark it as completed
boolean executionIsCompleted = true;
runtimeService.deleteMultiInstanceExecution(executionId, executionIsCompleted);|
Ensure that the execution you are trying to delete is not currently active or in a state that would prevent deletion. If there are concurrent transactions or dependencies, you may encounter exceptions. |
Execution Properties
Executions have the same properties as process instance. See the table above.
Task Instances
A task instance represents a specific occurrence of a task within a process. When a process execution reaches a user task, service task, or any other type of task, a task instance is created. Task instances are used to track and manage the execution of tasks by users or systems.
Standalone Tasks
You can create standalone tasks that are not directly tied to a specific process instance. This feature provides additional flexibility for task management in various scenarios. For example:
Task newTask = taskService.newTask();
newTask.setName("Standalone Task");
newTask.setAssignee("userId"); // Assign to a user
taskService.saveTask(newTask);Accessing Task Instances
Task instances can be accessed programmatically through API using the TaskService.
For example:
//Getting task by ID
Task task = taskService.createTaskQuery().taskId(taskId).singleResult();
//Getting a list of tasks, assigned to user
List<Task> tasks = taskService.createTaskQuery().taskAssignee("userId").list();Storing Task Instances
Active task instances are stored in the database, specifically in tables ACT_RU_TASK.
Each task instance is associated with its corresponding process instance and execution context.
Deleting Task Instances
Technically, it is possible to delete tasks programmatically:
taskService.deleteTask(taskId, "Reason for deletion");|
But the deletion of a task can significantly affect the associated process in several ways. So, deletion of tasks must be done with caution, as it typically requires specifying criteria to avoid unintended data loss. |
Task Instance Properties
| Property | Description |
|---|---|
Id |
Unique identifier for the task instance. |
Execution Id |
Identifier of the execution associated with the task. |
Process Instance Id |
Identifier of the process instance to which the task belongs. |
Process Definition Id |
Identifier of the process definition associated with the task. |
Task Definition Id |
Identifier of the task definition that this instance is based on. |
State |
Current state of the task (e.g., created, assigned, completed). |
Name |
Name of the task as defined in the BPMN model. |
Description |
Description providing additional details about the task. |
Task Definition Key |
Key used to reference the task definition in queries. (It is equal to parameter 'task id' in the process model.) |
Owner |
Identifier of the user who owns the task. |
Assignee |
Identifier of the user currently assigned to complete the task. |
Delegation |
Identifier for any delegation associated with this task. |
Priority |
Priority level assigned to this task, influencing its order in processing. |
Create Time |
Time when the task was created. |
In Progress Time |
Time when work on the task began. |
In Progress Started By |
Identifier of the user who started working on this task. |
Claim Time |
Time when the task was claimed by a user. |
Claimed By |
Identifier of the user who claimed this task. |
Suspended Time |
Time when the task was suspended, if applicable. |
Suspended By |
Identifier of the user who suspended this task. |
In Progress Due Date |
Due date for completing work on this task while it is in progress. |
Due Date |
Final due date by which this task must be completed. |
Category |
Category or type classification for this task. |
Suspension State |
State indicating whether the task is suspended or active. |
Process Variables
In BPMN, process variables represent data used during the execution of a process instance. They serve as containers for information that can influence the flow of the process, store intermediate results, or provide input to tasks and activities.
Variables can be used in expressions, for example, to select the correct outgoing sequence flow in an exclusive gateway. In service tasks, they can be used when calling external services, for example, to provide the input or store the result of the service call, and so on.
Persisting Process Variables
Unlike regular Java variables, process variables are entities managed by process engine. The engine creates instances of process variables when the process started or when new variables are defined and initialized.
So, they are really containers, storing the value of known Java types.
Types of Process Variables
In Jmix BPM, supported variable types are:
-
String
-
Multiline string
-
Decimal
-
Number
-
Boolean
-
Date
-
Date with time
-
Entity
-
Entity list
-
File
-
Platform enum
-
Object (not available in process forms)
Entities here are considered as Jmix entities defined in the data model.
When such variables are persisted, the process engine de-facto stores in the database in the following format:
<entity-name>."<UUID>"", for example:
jbt_User."60885987-1b61-4247-94c7-dff348347f93"
So when the process uses this variable later, it reads the actual stated of the entity.
|
When using variables of entities list type, take care of the list size that is limited by 4000 characters. Suppose, we need 50 characters for the one entity, so the list size will be approximately 80. If the length of the process variable exceeds the limit, it causes an exception when persisting. But it is possible to use variables of longer size within a transaction boundaries while persisting is not required. As well, you can use transient variables. |
Variable Scopes
Process variables have a defined scope, typically associated with a specific process instance. This means they are accessible throughout the execution of that instance but may not be visible outside it. Thus, any task, subprocess, or event within the same process instance can read from and write to these variables. A process instance can have any number of variables.
However, it’s important to note that while process instance variables are visible across all embedded scopes (like subprocesses), they are not accessible from separate process instances. For example, if a subprocess is called using a "call activity," any variables must be explicitly passed between the parent and child processes; they do not automatically inherit the parent’s variables.
This design ensures that each process instance maintains its own state and data integrity while allowing flexibility in managing information across various tasks within that instance.
Local Variables
Local variables in BPMN are variables that exist within a specific scope, typically tied to a particular task or subprocess. Within multi-instance activities, local variables can be defined for each instance. They are used to store data that is relevant only within that scope and are not accessible outside it. Scopes can be nested.
Local variables are created when the block of logic is entered and are automatically deleted when the block is exited. This behavior helps manage memory efficiently by ensuring that resources are freed up when they are no longer necessary.
Local variables can have the same name as variables in higher scopes (like process instance) without causing conflicts. When referenced within their scope, they override any higher-scoped variable with the same name.
Transient Variables
Transient variables are variables that behave like regular variables, but are not persisted. Typically, transient variables are used for advanced use cases. When in doubt, use a regular process variable.
Using Process Variables
You can pass variables into the process instance when starting the process:
ProcessInstance startProcessInstanceByKey(String processDefinitionKey, Map<String, Object> variables);Variables can be added during process execution.
For example, via RuntimeService:
void setVariable(String executionId, String variableName, Object value);
void setVariableLocal(String executionId, String variableName, Object value);
void setVariables(String executionId, Map<String, ? extends Object> variables);
void setVariablesLocal(String executionId, Map<String, ? extends Object> variables);Variables can also be retrieved, as shown below.
Note that similar methods exist on the TaskService.
This means that tasks, like executions, can have local variables that are 'alive' just for the duration of the task.
Map<String, Object> getVariables(String executionId);
Map<String, Object> getVariablesLocal(String executionId);
Map<String, Object> getVariables(String executionId, Collection<String> variableNames);
Map<String, Object> getVariablesLocal(String executionId, Collection<String> variableNames);
Object getVariable(String executionId, String variableName);
<T> T getVariable(String executionId, String variableName, Class<T> variableClass);Variables are often used in Java delegates, expressions, execution listeners, task listeners, scripts, and so on. In those constructs, the current execution or task object is available, and it can be used for variable setting and/or retrieval. The simplest methods are these:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);|
A variant with "local" is also available for all of the above. |
Process Variable Properties
| Property | Description |
|---|---|
ID |
A unique identifier for the process variable. |
Type |
Defines the type of data that the variable can hold, such as String, Integer, Boolean, etc. |
Name |
The name of the variable. |
Execution ID |
Refers the execution, in which scope the process variable is defined. |
Process instance ID |
Refers the process instance, in which scope the process variable is defined. |
Task instance ID |
Refers the task instance, in which scope the process variable is defined. |
